Mastering the Fundamentals of Kubernetes Autoscaling
Summarize With:
While operating data in a cluster, the demand for computer resources remains dynamic where in some cases, the resource requirement would be high while in others, it could be drastically low. Allocating the same resources for every situation can lead to massive waste, while manually performing resource adjustments could require much effort. The solution to that issue is kubernetes autoscaling. This article will help you to learn about Kubernetes Autoscaling, why it helps, its types, and best practices.
What is Kubernetes Autoscaling?
Autoscaling in Kubernetes is the eradication of manually scaling up or down the resources as per a change in conditions. As the name suggests, it performs the scaling of clusters through automation for better resource utilization and reducing overall costs. It can also be used simultaneously with the cluster autoscaler to utilize only the required resources. Kubernetes Autoscaling ensures that the cluster remains available even when running at a peak capacity. There are two Kubernetes Autoscaling mechanisms.
- Pod-based scaling: This mechanism is supported by the Vertical Pod Autoscaler (VPA), and the Horizontal Pod Autoscaler (HPA).
- Node-based scaling: The node-based scaling mechanism is supported by the Cluster Autoscaler.
Benefits of Kubernetes Autoscaling :
Kubernetes Autoscaling has proven to be beneficial for organizations' operating clusters. Here are some of the significant benefits you can expect from Kubernetes Autoscaling.
- Cost Saving: Without autoscaling, the resources consumed in the clusters will either be too much or too low. As autoscaling can adjust the resources as required by the clusters, it ensures they are utilized efficiently and without any waste. With better resource utilization, the overall cost will come down drastically.
- Reduce Manual Efforts: If you are not using autoscaling, you would need to manually allocate the resources for the cluster whenever the application requires it. Not only will it require a lot of manual effort, but it can also lead to extreme wastes of time. Autoscaling can solve all these issues, reducing many manual efforts required for resource allocation.
Types of Kubernetes Autoscaling :
There are three most widely used types of Kubernetes Autoscaling. The below section will explain all about these Autoscaling types and how it helps in minimizing cluster costs.
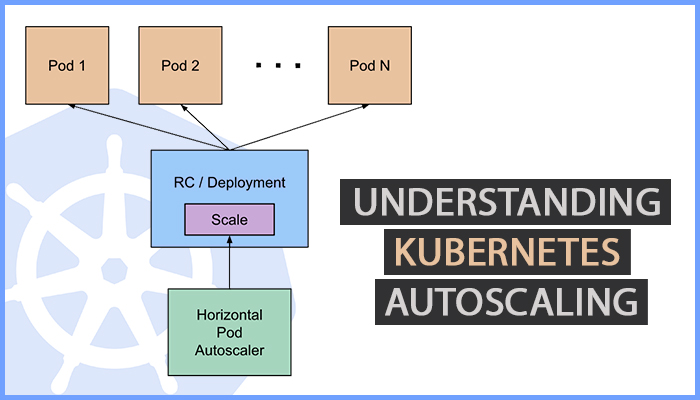
#1: Horizontal Pod Autoscaler (HPA):
There are stances when an application faces fluctuations in usage. In that case, the best action is either adding or removing pod replicas. Horizontal Pod Autoscaler deploys additional pods in the Kubernetes cluster automatically when the load increases. It modifies the entire workload resource and scales it automatically as per requirement. Whether scaling up or scaling down the pods, HPA can do it automatically to meet the load.
The Working of HPA:
HPA follows a systematic approach while modifying the pods. It understands whether or not the pod replicas need to be increased or decreased by taking the mean of a per-pod metric value. Afterward, it analyzes whether raising or reducing the pod replicas will bring the mean value near to the desired number. This autoscaler type is managed by the controller manager, and it runs as a control loop. Both stateless apps and stateful workloads can be handled through HPA.
For instance, if five pods are performing currently, your target utilization is fifty percent, and the current usage is nearly seventy-five percent. In that case, the HPA controller will add three pod replicas in the cluster to bring the mean number near the fifty percent target.
Limitations of HPA:
HPA has a few limitations that should be kept in mind before implementation. One limitation is that you cannot configure it on a Replication Controller or a RecaSet while using a Deployment. Furthermore, it is always advised to avoid using HPA with VPA on the CPU.
Best Practices for using HPA:
For the best outcome from HPA, experts recommend using the following practices:
- Custom Metrics: HPA supports pod and object metrics as custom metrics. Using custom metrics as the source for making the right decisions from HPA is an effective way of autoscaling. However, using the right type as per the requirement is the key to getting the desired results. If the team is highly skilled, they can also use third-party monitoring systems to add external metrics.
- Value configuration for every container: The decisions made by HPA remain accurate only when the values are included for each container. Failing to do so may lead to inaccuracies in making the scaling decisions. The right practice is ensuring that every container's value is configured correctly.
#2: Vertical Pod Autoscaler (VPA):
In several instances, containers focus on the initial requests instead of upper-limit requests. Due to this reality, the default scheduler of Kubernetes overcommits the CPU reservations and the node's memory. In this situation, the VPA can increase or decrease these requests to ensure the usage remains within the resources.
In simpler terms, VPA is the tool that can resize pods for efficient memory and CPU resources. It increases the CPU reservations automatically as per the application and can also increase the utilization of cluster resources. It only consumes necessary resources while it ensures that the pod makes the most out of the cluster nodes. In addition, it can make changes in the memory requests automatically, it drastically reduces the time consumed in maintenance.
Working of VPA:
The basic working of the vertical pod autoscaler consists of three different components, which are briefly explained below:
- Admission controller: This component overwrites the pods' resource requests after they are created.
- Recommender: It calculates the overall target values which will be used for autoscaling and evaluates the utilization of resources.
- Updater: The updater monitors the pod's resource limits and checks whether they need updating or not.
Limitations of VPA:
The minimum memory allocation in VPA is 250 MB, which is one of its major limitations. If the requests are smaller, they will be increased to fit this number automatically. Apart from that, it cannot be used for individual pods that do not have an owner. Furthermore, if you want to enable VPA on components, you need to ensure that they have a minimum of two healthy replicas running, or you need to autosize them.
Best Practices for using VPA:
Here are the best practices for VPA that the experts recommend:
- Run VPA with updateMode: Off: Most veterans recommend running VPA with updatedMode: Off as it allows the user to identify the usage of resources of the pods that will be autoscaled. Doing so will provide recommended memory and CPU requests which can be used later.
- Avoid Using VPA and HPA Together: VPA and HPA are incompatible, and they should not be used for the same pod sets. However, exceptions can be made if the HPA is configured to use external or custom metrics.
#3: Cluster Autoscaler
In case you want to optimize costs through dynamic scaling the number of nodes, Cluster Autoscaler is the mechanism for you. It modifies the number of nodes in a cluster on all the supported platforms and works on the infrastructure level. However, due to this reason, it requires permission to add or remove infrastructures. All these factors make it suitable for workloads that face dynamic demand.
Another action by cluster autoscaler is scanning the managed pool's nodes to reschedule the pods on other cluster nodes and remove them if found.
Working of Cluster Autoscaler:
The Cluster Autoscaler looks for pods that cannot be scheduled and determines whether consolidating the currently deployed pods to run them on lower node numbers is possible or not. If it is possible, it evicts and eradicates them.
Limitations of Cluster Autoscaler:
Unlike other Kubernetes autoscaling mechanisms, the cluster autoscaler does not rely on memory or CPU usage for making scaling decisions. Instead, it monitors the pod's requests and limits for memory resources. Due to this process, the cluster can have low utilization efficiency. Apart from that, the cluster autoscaler will issue a scale-up request every time there is a need to scale up the cluster. This request can take between thirty to sixty seconds. However, the time consumed to create a node can be higher, impacting the application performance.
Cluster Autoscaler Best Practices:
Below are the best practices that should be followed while deploying the cluster autoscaler.
- Use the right Kubernetes Version: Before you begin deploying the cluster autoscaler, you need to ensure that either you have the latest version of Kubernetes or the recommended Kubernetes version compatible with the cluster autoscaler.
- Have Resource Availability for Cluster Autoscaler Pod: You need to make sure that resources are available for the cluster autoscaler pod. To do that, you need to define at least one CPU for resource requests made to the cluster autoscaler pod. If this requirement is not met, the cluster autoscaler may stop responding.
Karpenter:
Karpenter is another Kubernetes Cluster autoscaler that is built on Amazon Web Services. This open-source and high-performing autoscaler can enhance the availability of the application and the efficiency of the cluster through rapid deployment of the required resources depending on the varying requirements.
Licensed under Apache License 2.0, it can work with any Kubernetes cluster in any environment. Moreover, it can perform anywhere, including managed node groups, AWS Fargate, and self-managed node groups.
Upon successful installation of Karpenter, it analyses the resource requests of unscheduled pods. Afterward, it makes the necessary decisions for releasing new nodes and terminating them to minimize costs and latencies related to scheduling.
Kubernetes — Event-Driven Autoscaling:
Kubernetes-based Event-Driven Autoscaling or KEDA is also an open-source component that helps use event-driven architecture to benefit Kubernetes workload. KEDA scales the Kubernetes deployment horizontally and allows users to define the criteria for autoscaling based on the event source and metrics information. This functionality allows the user to choose from different pre-defined triggers that function as metrics or event sources while autoscaling. KEDA contains two components which are explained below.
- KEDA Operator: With the KEDA operator, end-users can scale workloads in/out from zero to N instances through support for Jobs, Kubernetes Deployments, or any custom resource that defines subresource as /scale.
- Metrics Server: Autoscaling actions like the number of events in the Azure event hub or messages in Kafka topic can be done through metric servers as it exposes external metrics to HPA in Kubernetes. However, KEDA should be the only metric adapter in the system because of the upstream limitations.
How Does Kubernetes Cluster Autoscaler Work?
The Cluster Autoscaler does not function like the HPA or VPA as it does not look at CPU or memory when it activates autoscaling. Rather, it takes action based on events and checks for pods that are not scheduled. If there are any unschedulable pods in the cluster, the cluster autoscaler will commence creating a new node.
There are instances when the user may have node groups of numerous node types. In that case, the cluster autoscaler will choose the most suitable strategies among the following:
- Most Pods — Here, the cluster autoscaler will pick the node group to schedule the maximum pods.
- Random — The default strategy of the cluster autoscaler where a random node type will be picked.
- Priority — The node group with the highest priority will be selected by the cluster autoscaler.
- Least Waste — The node group with the minimum ide CPU after scaling-up will be picked.
- Price — Here, the node group that will cost the minimum will be picked by the cluster autoscaler.
After identifying the most suitable node type, the cluster autoscaler will call the API for provisioning a new compute resource. This action may vary with the cloud services the user is using.
For instance, the cluster autoscaler will provision a new EC2 instance for AWS, whereas a new virtual machine will be created on Azure, and a new compute engine will be created on the Google Cloud Platform.
Upon completing the compute resource, the node will be added to the cluster so that the pods that are not scheduled can be deployed.
Kubernetes Autoscaling by ThinkSys
Autoscaling is an essential aspect to working with clusters. Having professional assistance in this task can be a boon as it eradicates the possibility of error. ThinkSys is a renowned name in offering Kubernetes Autoscaling services and consulting.
Not just streamlining the CI/CD process, but practical usage of clusters can be achieved through Kubernetes autoscaling services by ThinkSys. Here are the different Kubernetes services that ThinkSys offers:
1.Kubernetes Autoscaling:
Our Kubernetes Autoscaling will help you ensure that your clusters always have the required resources to perform effectively and efficiently.
- Rapid scaling up and down of resources.
- Analyze clusters and use HPA, VPA, or cluster autoscaling accordingly.
- Can perform with all the leading cloud providers, including AWS, Azure, and GCP.
- Use the right tools and practices for the best autoscaling.
2. Kubernetes Consulting:
Whether you want full-fledged services or consulting regarding Kubernetes, the professionals at ThinkSys can assist you in fulfilling all your needs.
- Assistance regarding implementing Kubernetes in your organization.
- Containerizing applications for better working of your business.
- Understand all the requirements necessary for Kubernetes autoscaling.
- Advisory services for Kubernetes so that you always remain aware of the right ways.
3. Kubernetes Autoscaling Support:
Support is an integral part of any service. At ThinkSys, we take extraordinary measures to provide continuous support to our clients so that their issues can be immediately fixed.
- 24X7 support for Kubernetes autoscaling.
- Tracking and monitoring so that any issue can be diagnosed quickly.
- Analyzing the system for any underlying issues and fixing them ASAP.
FAQ(Kubernetes AutoScaling)
Q1: What is Kubernetes Autoscaling?
Kubernetes autoscaling is the process of automatically scaling up or down the resources in a cluster as the load increases or decreases. It ensures that resources are optimally utilized in a cluster.
Q2: What is the difference between Kubernetes HPA and VPA?
The primary difference between Kubernetes HPA and VPA is that the former increases or decreases the number of pods, whereas the latter does the same but with the pod resources rather than the number of pods.
Q3: What is the difference between Kubernetes Autoscaling and Load Balancing?
In Kubernetes autoscaling, the resource allocation varies as per the cluster requirement. On the other hand, load balancing is about allocating resources equally in every available zone in a region.
Q4: What are the autoscaling options with EKS?
The Amazon Elastic Kubernetes Service supports Kubernetes Cluster Autoscaler and Karpenter for Kubernetes autoscaling.